Customer success teams sit on a goldmine of signals—tickets, chats, NPS comments, usage patterns—yet privacy expectations and regulations make many leaders hesitant to mine that gold. The answer isn’t to collect more data; it’s to analyze smarter. This article outlines how to optimize support outcomes with analytics that respect user rights and withstand legal scrutiny—no implementation steps, just strategy you can use to set direction.
What “privacy-compliant” analytics really means
Privacy-compliant customer success analytics shifts focus from individual surveillance to purpose-bound, aggregate insight. The goal is to improve time-to-resolution, quality, and retention while minimizing what you collect and who can see it.
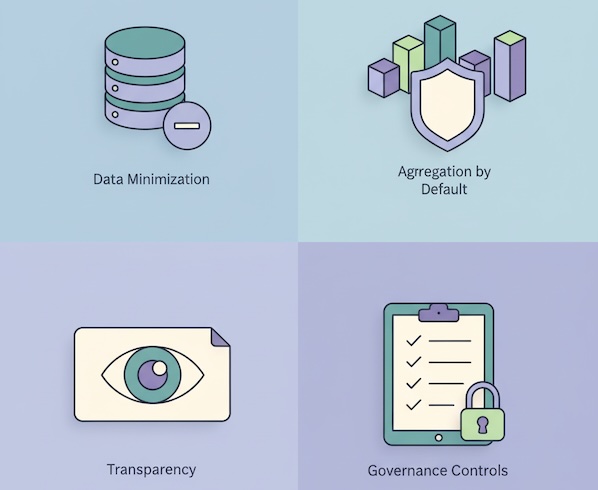
Principles to anchor on:
- Data minimization: Capture only signals tied to a legitimate business purpose (e.g., resolving issues faster, preventing churn).
- Aggregation by default: Report at cohort, queue, or product-module level; restrict person-level drill-downs to cases with a clear, documented need.
- Transparency: Stakeholders know which metrics are modeled vs. observed, and how text is processed.
- Governance: Clear ownership, review cycles, and audit logs for metrics and models.
The outcomes that matter (and privacy-safe ways to gauge them)
Think in terms of outcomes (customer value delivered) rather than activity counts.
1) Resolution efficiency
- Time to First Response (TFR) and Time to Resolution (TTR) by channel, severity, language, and product area.
- First-Contact Resolution (FCR) rate segmented by issue type (billing vs. technical).
Privacy-safe angle: analyze at queue/product granularity; redact free-text examples used for training.
2) Quality and sentiment
- Quality Assurance (QA) distribution (pass/needs-improvement) by macro, template, or playbook.
- Conversation sentiment trend at aggregate level (shift from negative → neutral → positive within a case).
Privacy-safe angle: use on-the-fly NLP with entity redaction and store only sentiment vectors or labels.
3) Effort and deflection
- Customer Effort Score (CES) and self-service deflection rate (help center views that prevent tickets).
- Recontact rate within 7–14 days for the same intent.
Privacy-safe angle: intent is derived from content clusters, not persistent identity across channels.
4) Business impact
- Churn-adjacent signals: proportion of tickets filed within 30 days before downgrades.
- Expansion-adjacent signals: resolution of blockers preceding upgrades or feature adoption.
Privacy-safe angle: analyze at cohort (plan, region, industry), not individual accounts, and report in bins or ranges.
Turning text into insight—without exposing people
Support data is text-heavy and sensitive. You can still learn a lot while protecting customers and agents.
- Theme detection & clustering: Group tickets by normalized intent (e.g., “failed login,” “billing dispute,” “API quota”). Store the cluster ID and counts, not raw transcripts.
- Outcome labeling: Was the customer satisfied? Did they confirm the fix? Keep outcomes as labels, not verbatim text.
- Risk triage: Identify patterns that precede escalations or refunds at the cluster level to prioritize fixes.

Guardrails to insist on:
- Automated redaction of PII/PHI before any analysis (names, emails, card numbers, order IDs).
- Short retention windows for raw text used in model evaluation.
- Access controls that separate model training roles from frontline viewing rights.
A privacy-first KPI set for Customer Success
Build a compact, decision-grade scorecard executives can trust:
Service Health
- TFR/TTR by severity band (p50/p90)
- FCR rate by intent cluster
- QA pass rate and coaching coverage
Customer Experience
- Aggregate conversation sentiment shift (start → end)
- CES trend (ticketed vs. self-served)
- Recontact rate (same intent, 14-day window)
Operational Efficiency
- Assist rate from macros/playbooks (and their win rate)
- Deflection effectiveness (help-center views leading to no ticket within 48h)
- Backlog burn-down and SLA attainment
Business Linkage
- Churn-adjacent ticket ratio (by plan/region)
- Expansion-adjacent resolution ratio (removal of blockers preceding upsell)
- Prevented escalations (tickets resolved before breach thresholds)
Each metric should state: purpose, grain, and privacy guardrails (e.g., “cohort-level only; no raw text retained”).

Modeling you can defend to Legal and to customers
You don’t need to profile people to get predictive value.
- Queue load & staffing forecasts: Time-series models use counts by hour/day and severity, not identities, to plan coverage.
- Escalation risk at cluster level: Predict which intent clusters are likely to breach SLAs and pre-stage guidance or specialist routes.
- Satisfaction drivers: Shapley/feature-importance summaries on aggregate vectors (channel, wait time, resolution steps) reveal what truly moves CSAT—explainable and privacy-safe.
Protection techniques worth knowing (and naming in your policy docs):
- Differential privacy: Add calibrated noise to small-n slices, publish only when thresholds are met.
- K-anonymity & suppression: Hide or merge segments until they exceed a minimum case count.
- Secure aggregation: Combine encrypted metrics so no single record is ever exposed in transit or storage.
Coaching and content, without spotlighting individuals
Use analytics to improve the system, not to micromanage people.
- Macro/playbook effectiveness: Rank templates by FCR and TTR reduction to evolve your knowledge base. Celebrate what works, not who used it.
- Skill routing & enablement: Identify intents that benefit from specialized paths (billing, SSO, advanced API). Provide team-level training where gaps show up.
- Feedback loops to product: Quantify how much TTR is saved when a specific UI copy or flow changes—share cohort-level wins with Product and Marketing.
Pitfalls to avoid (and better alternatives)
- Pitfall: Storing raw transcripts for “future analysis.”
Better: Redact instantly; keep hashed references and minimal feature representations. - Pitfall: Chasing per-agent leaderboards.
Better: Track team-level improvement; use QA and calibrated reviews for individual coaching in private. - Pitfall: Reporting modeled numbers as facts.
Better: Label modeled metrics, include confidence bands, and disclose thresholds. - Pitfall: Over-segmenting until every slice is small.
Better: Enforce minimum cohort sizes; roll up rare segments to preserve anonymity.
Executive questions to keep analytics honest
- What decision does this metric change? If none, you don’t need it.
- What’s the minimum data to answer that question? Cut the rest.
- At what grain is this reported? Prefer page/queue/cluster over person.
- Could someone be re-identified from this view? If yes, aggregate or suppress.
- How are we validating models? Out-of-time tests, stability checks, and bias audits.
- What’s our rollback plan? Know how to freeze or retire a metric/model fast.
The business case (in plain numbers)
Privacy-compliant customer success analytics typically delivers:
- TTR reductions (10–30%) via better routing and macro evolution.
- Higher FCR (5–15 pts) by focusing on intents with the strongest quality gaps.
- Lower recontact rates (10–25%) through fix-once documentation and product feedback.
- Improved retention in at-risk cohorts as escalations drop and effort falls.
These gains come from system improvements—smarter queues, clearer content, targeted coaching—not from expanding the data footprint.
Bottom line
Customer success analytics doesn’t need to trade privacy for performance. By minimizing data, aggregating results, and being transparent about what’s modeled versus observed, you can optimize support outcomes and strengthen trust at the same time. The organizations that win will be those that treat privacy not as a constraint, but as a design principle—and still deliver faster answers, fewer escalations, and customers who feel genuinely cared for.